
Preface#
Previously, I set up an anime media library using Jellyfin, but the VPS connection was somewhat unsatisfactory, and there was a risk of running out of bandwidth. So, with the great spirit of free riding free 😇, I discovered that I could use strm files to achieve direct playback of videos in OneDrive through Jellyfin, without using the server's bandwidth and traffic. I also found a conversion script on GitHub, and everything was just perfect 😜.
The principle is roughly as follows:
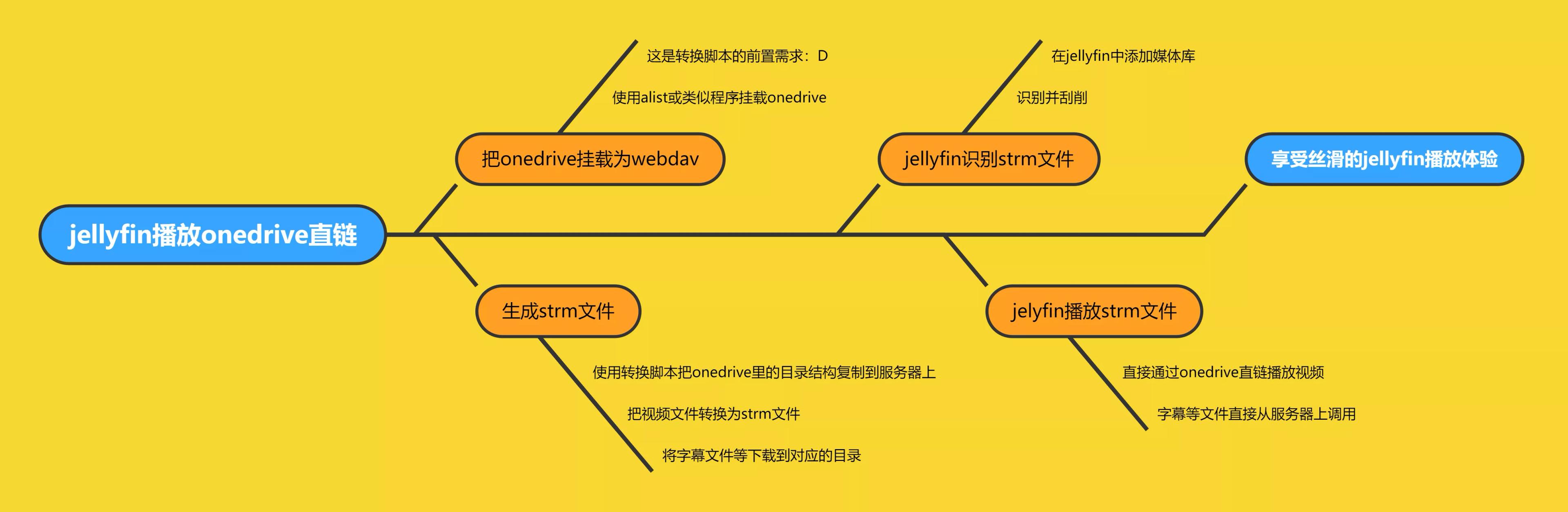
Preparation#
- A server with Jellyfin installed
- A well-structured OneDrive media library
- An Alist that has mounted the OneDrive media library
- Some patience
Preparing the Script Runtime Environment#
Make sure that python3 and pip are installed on your server. Use the following commands to check if they are installed:
python3 --version
pip --version
If they are not installed, please follow the steps below to install them:
-
Update the package list:
Open the terminal and first update your package list. This ensures that you download the latest software packages. Run the following command:
apt update -
Install Python 3:
The Debian software repository includes installation packages for Python 3. Run the following command to install Python 3:
apt install python3 -
Install pip:
Pip is the package manager for Python, used to install and manage Python packages. Install it using the following command:
apt install python3-pip -
Verify the installation:
After installation, run the following commands to verify that Python 3 and pip are correctly installed:
python3 --versionpip3 --version
Once you have confirmed the installation, create a virtual environment and install the script's environment dependencies within it:
-
Create a virtual environment
Creating a virtual environment can avoid certain conflicts 🤗
python3 -m venv /python_env/auto_film/Please replace
/python_env/auto_film/with the path where you want to install the virtual environment. -
Activate the virtual environment
After creating it, you need to activate it 🧐
source /python_env/auto_film/bin/activateReplace
/python_env/auto_film/with the path where you just installed the virtual environment. -
Install dependencies
webdavclient3is a Python library for interacting with WebDAV servers.pip install webdavclient3
Okay, you have set up the environment required to run the script 👌
Since the script may take a long time to run, you can choose to install screen to allow the command to run in the background, so you can close the terminal window running the script 😉.
-
Install screen
Use the following command to install
screen:apt-get install screen -
Start screen:
Create a new session:
screen -S mysessionReplace
mysessionwith your desired session name. -
Using the screen session:
In the
screensession, you can use the command line as usual. You can also close this terminal window, and the commands will continue to run in the background. -
Reconnect to a screen session:
To reconnect to an existing
screensession, use:screen -r mysessionWhere
mysessionis your custom session name.
Preparing the strm Script#
Save the following code as autofilm.py. The script content comes from Akimio521's GitHub project AutoFilm. Give the author a star ✨.
from webdav3.client import Client
import argparse, os, requests, time
'''
Function to traverse the WebDAV server
If depth is None, it will recursively traverse the entire WebDAV server
If depth is a positive integer, it will recursively traverse to the specified depth
If depth is 0, it will only traverse the files and folders in the current folder, without continuing to recursively traverse the next level of folders.
'''
def list_files(webdav_url, username, password, show_path, depth=None, path='', count=0, proxies=None):
options = {
'webdav_hostname': webdav_url,
'webdav_login': username,
'webdav_password': password,
'proxies': proxies
}
client = Client(options)
directory = []
files = []
q = 1
while q < 15:
try:
items = client.list()
except:
print(f'Connection failed for the {q} time, retrying in {q+1} seconds...')
q += 1
time.sleep(q)
else:
if q > 1:
print('Reconnection successful...')
break
if q == 15:
print('Connection failed, please check your network settings!')
exit()
for item in items[1:]:
if item[-1] == '/':
if depth is None or depth > 0:
subdirectory, subfiles, count = list_files(webdav_url + item, username, password, show_path, depth=None if depth is None else depth - 1, path=path+item, count=count)
directory += [item + subitem for subitem in subdirectory]
files += [item + subitem for subitem in subfiles]
else:
directory.append(item)
else:
files.append(item)
count += 1
if show_path and path:
print(f'Current folder path: {path}')
return directory, files, count
'''
Download function
Used for downloading 'ASS', 'SRT', 'SSA', 'NFO', 'JPG', 'PNG' files
'''
def download_file(url, local_path, filename, total_count):
p = 1
while p < 10:
try:
print('Downloading: ' + filename)
r = requests.get(url.replace('/dav', '/d'), proxies=proxies)
os.makedirs(os.path.dirname(local_path), exist_ok=True)
with open(local_path, 'wb') as f:
f.write(r.content)
f.close()
except:
print(f'Download failed for the {p} time, retrying in {p + 1} seconds...')
p += 1
time.sleep(p)
else:
if p > 1:
print('Re-download successful!')
print(filename + ' downloaded successfully!')
break
progress = int((p / 10) * 100)
print(f'Completed {progress}%, total {total_count} files')
parser = argparse.ArgumentParser(description='Autofilm script')
parser.add_argument('--webdav_url', type=str, help='WebDAV server address', required=True)
parser.add_argument('--username', type=str, help='WebDAV account', required=True)
parser.add_argument('--password', type=str, help='WebDAV password', required=True)
parser.add_argument('--output_path', type=str, help='Output file directory', default='./Media/')
parser.add_argument('--subtitle', type=str, help='Whether to download subtitle files', choices=['true', 'false'], default='true')
parser.add_argument('--nfo', type=str, help='Whether to download NFO files', choices=['true', 'false'], default='false')
parser.add_argument('--img', type=str, help='Whether to download JPG and PNG files', choices=['true', 'false'], default='false')
parser.add_argument('--show_path', type=str, help='Whether to show folder path during traversal', choices=['true', 'false'], default='false')
parser.add_argument('--proxy', type=str, help='HTTP proxy server in the format IP:port')
args = parser.parse_args()
print('Startup parameters:')
print(f'WebDAV server address: {args.webdav_url}')
print(f'WebDAV login username: {args.username}')
print(f'WebDAV login password: {args.password}')
print(f'File output path: {args.output_path}')
print(f'Whether to download subtitles: {args.subtitle}')
print(f'Whether to download movie information: {args.nfo}')
print(f'Whether to download images: {args.img}')
print(f'Whether to show folder path during traversal: {args.show_path}')
proxies = None
if args.proxy:
proxies = {
'http': f'http://{args.proxy}',
'https': f'http://{args.proxy}'
}
directory, files, count = list_files(args.webdav_url, args.username, args.password, args.show_path, depth=None, path='', count=0, proxies=proxies)
urls = [args.webdav_url + item for item in directory + files]
download_count = 0
for url in urls:
if url[-1] == '/':
continue
filename = os.path.basename(url)
local_path = os.path.join(args.output_path, url.replace(args.webdav_url, '').lstrip('/'))
file_ext = filename[-3:].upper()
if file_ext in ['MP4', 'MKV', 'FLV', 'AVI', 'WMV']:
if not os.path.exists(os.path.join(args.output_path, filename[:-3] + 'strm')):
print('Processing: ' + filename)
try:
os.makedirs(os.path.dirname(local_path), exist_ok=True)
with open(os.path.join(local_path[:-3] + 'strm'), "w", encoding='utf-8') as f:
f.write(url.replace('/dav', '/d'))
except:
print(filename + ' processing failed, the filename contains special characters, it is recommended to rename it!')
elif args.subtitle == 'true' and file_ext in ['ASS', 'SRT', 'SSA', 'SUB']:
if not os.path.exists(local_path):
download_file(url, local_path, filename, count)
download_count += 1
elif args.nfo == 'true' and file_ext == 'NFO':
if not os.path.exists(local_path):
download_file(url, local_path, filename, count)
download_count += 1
elif args.img == 'true' and file_ext in ['JPG', 'PNG']:
if not os.path.exists(local_path):
download_file(url, local_path, filename, count)
download_count += 1
progress = int((download_count / count) * 100)
print(f'Completed {progress}%, total {count} files')
print('Processing complete!')
Running the strm Script#
-
Start a screen session (optional):
Using screen allows you to close the terminal window running the script, letting it run in the background.
screen -S autofilm -
Activate the previously set up virtual environment
source /python_env/auto_film/bin/activate/python_env/auto_film/is the path where you created the virtual environment earlier. -
Run the script
Please ensure that all paths and filenames in the media library do not contain special characters like
#《, otherwise a network error will occur.python3 autofilm.py --webdav_url https://alist.example.com/dav/your/media/ --username uname --password pword --output_path /your/strm/ --nfo true --img true- Replace
https://alist.example.com/dav/with your Alist URL - Replace
your/media/with the path of your media library on Alist - Replace
unameandpwordwith your Alist username and password - Replace
/your/strm/with the location where you want to store the strm files
Some parameter explanations:
Required parameters
- webdav_url: WebDAV server address
- username: WebDAV account
- password: WebDAV password
Optional parameters
- output_path: Output file directory, default is a subdirectory Media in the current folder
- subtitle: Whether to download subtitle files, default is true
- nfo: Whether to download NFO files, default is false
- img: Whether to download JPG and PNG image files, default is false
- Replace
Okay, please drink ten cups of tea 🍵 or watch a movie 🎞, the script's running time depends on the size of your media library and server configuration, usually it will be 🤏 slow.
Jellyfin Playing strm Files#
Add a media library in Jellyfin, and select the location where you store the strm files. Jellyfin will automatically recognize and scrape them.
Try playing it, and you will find that it does not consume server bandwidth at all! 🎉
Epilogue#
Now you don't have to worry about server bandwidth, and I've made the Jellyfin server public. I'll add some old anime resources later, bye~
References
- AutoFilm
- [Promoting my own small project—AutoFilm](Promoting my own small project—AutoFilm)