
前言#
之前用 jellyfin 搭建了一个动漫媒体库,但是 vps 的线路实在是有点不尽如人意,而且流量还有不够用的风险。于是凭借伟大的白嫖免费精神😇,我发现可以用 strm 文件来实现 jellyfin 直链播放 onedrive 里的视频,而不会走服务器的宽带和流量。我还在 github 上找到了一个转换脚本,一切都刚刚好😜。
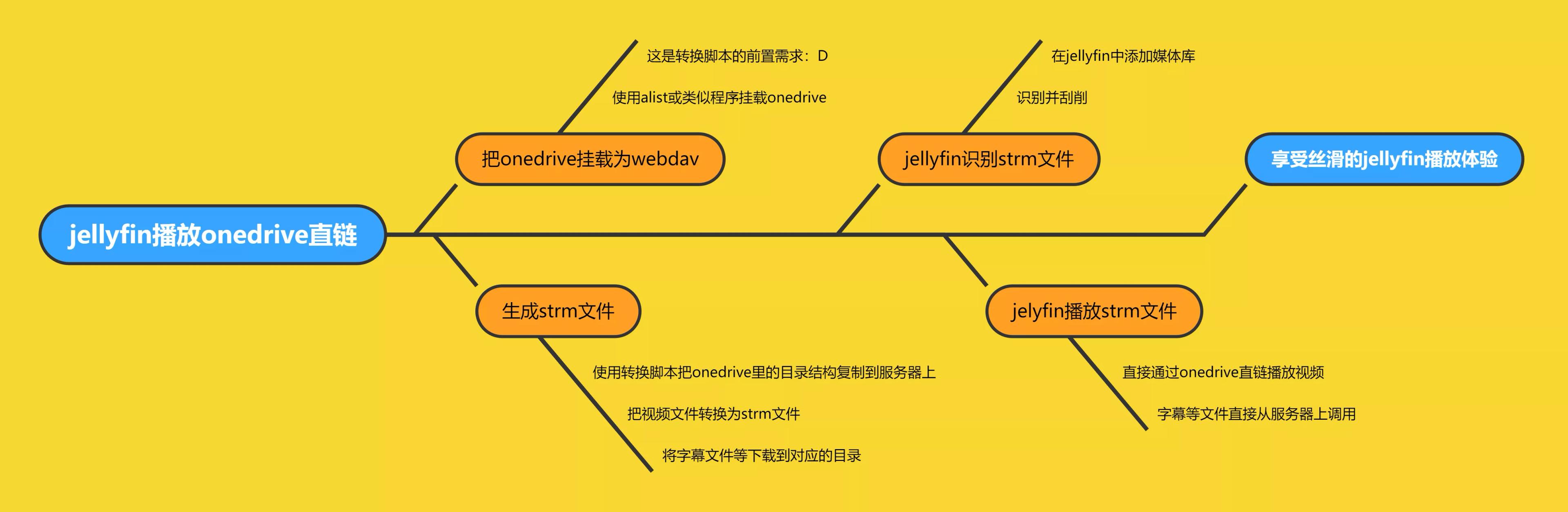
原理大概是这样:
准备#
- 装有 jellyfin 的服务器
- 结构清晰的 onedrive 媒体库
- 挂载了 onedrive 媒体库的 alist
- 一些耐心:D
脚本运行环境准备#
确保你的服务器中安装了python3和pip,使用以下命令检查是否安装:
python3 --version
pip --version
如果未安装,请依照以下步骤安装:
-
更新包列表:
打开终端,首先更新你的包列表。这确保你下载的是最新的软件包。运行以下命令:
apt update -
安装 Python 3:
debian 的软件仓库中包含了 python 3 的安装包。运行以下命令来安装 python 3
apt install python3 -
安装 pip:
pip 是 python 的包管理器,用于安装和管理 python 包。通过以下命令安装:
apt install python3-pip -
验证安装:
安装完成后,运行以下命令来验证 python 3 和 pip 是否正确安装:
python3 --versionpip3 --version
确保安装成功后,创建一个虚拟环境并在此环境中安装脚本的环境依赖:
-
创建虚拟环境
创建一个虚拟环境可以避免某些冲突🤗
python3 -m venv /python_env/auto_film/请将
/python_env/auto_film/替换为你想要安装虚拟环境的路径。 -
激活虚拟环境
创建后当然要激活的咯🧐
source /python_env/auto_film/bin/activate把
/python_env/auto_film/替换为你刚刚安装虚拟环境的路径。 -
安装依赖
webdavclient3是一个用于与 webdav 服务器交互的 python 库。pip install webdavclient3
ok,你已经把脚本运行所需的环境搭建好了👌
因为脚本运行时间较长,你可以选择安装一个screen来让命令可以在后台运行,这样你就可以把运行脚本的终端窗口关掉了😉
-
安装 screen
使用以下命令安装
screen:apt-get install screen -
启动 screen:
创建一个新的会话:
screen -S mysession把
mysession更换为你想要的会话名称。 -
使用 screen 会话:
在
screen会话中,你可以像平常一样使用命令行。而且你可以关闭这个终端窗口,这个窗口的命令会在后台运行。 -
重新连接到一个 screen 会话:
要重新连接到一个已经存在的
screen会话,使用:screen -r mysession其中
mysession是你自定义的会话名称。
准备 strm 脚本#
把以下代码保存为autofilm.py
脚本内容来自Akimio521佬的 github 项目 AutoFilm
给大佬递 star✨
from webdav3.client import Client
import argparse, os, requests, time
'''
遍历Webdav服务器函数
如果depth为None,则会递归遍历整个WebDAV服务器
如果depth为正整数,则会递归遍历到指定深度
如果depth为0,则只会遍历当前文件夹中的文件和文件夹,不会继续递归遍历下一级文件夹。
'''
def list_files(webdav_url, username, password, show_path, depth=None, path='', count=0, proxies=None):
options = {
'webdav_hostname': webdav_url,
'webdav_login': username,
'webdav_password': password,
'proxies': proxies
}
client = Client(options)
directory = []
files = []
q = 1
while q < 15:
try:
items = client.list()
except:
print(f'第{q}次连接失败,{q+1}秒后重试...')
q += 1
time.sleep(q)
else:
if q > 1:
print('重连成功...')
break
if q == 15:
print('连接失败,请检查网络设置!')
exit()
for item in items[1:]:
if item[-1] == '/':
if depth is None or depth > 0:
subdirectory, subfiles, count = list_files(webdav_url + item, username, password, show_path, depth=None if depth is None else depth - 1, path=path+item, count=count)
directory += [item + subitem for subitem in subdirectory]
files += [item + subitem for subitem in subfiles]
else:
directory.append(item)
else:
files.append(item)
count += 1
if show_path and path:
print(f'当前文件夹路径:{path}')
return directory, files, count
'''
下载函数
用于'ASS', 'SRT', 'SSA','NFO','JPG', 'PNG'文件的下载
'''
def download_file(url, local_path, filename, total_count):
p = 1
while p < 10:
try:
print('正在下载:' + filename)
r = requests.get(url.replace('/dav', '/d'), proxies=proxies)
os.makedirs(os.path.dirname(local_path), exist_ok=True)
with open(local_path, 'wb') as f:
f.write(r.content)
f.close()
except:
print(f'第{p}次下载失败,{p + 1}秒后重试...')
p += 1
time.sleep(p)
else:
if p > 1:
print('重新下载成功!')
print(filename + '下载成功!')
break
progress = int((p / 10) * 100)
print(f'已完成 {progress}%,共 {total_count} 个文件')
parser = argparse.ArgumentParser(description='Autofilm script')
parser.add_argument('--webdav_url', type=str, help='WebDAV服务器地址', required=True)
parser.add_argument('--username', type=str, help='WebDAV账号', required=True)
parser.add_argument('--password', type=str, help='WebDAV密码', required=True)
parser.add_argument('--output_path', type=str, help='输出文件目录', default='./Media/')
parser.add_argument('--subtitle', type=str, help='是否下载字幕文件', choices=['true', 'false'], default='true')
parser.add_argument('--nfo', type=str, help='是否下载NFO文件', choices=['true', 'false'], default='false')
parser.add_argument('--img', type=str, help='是否下载JPG和PNG文件', choices=['true', 'false'], default='false')
parser.add_argument('--show_path', type=str, help='遍历时是否显示文件夹路径', choices=['true', 'false'], default='false')
parser.add_argument('--proxy', type=str, help='HTTP代理服务器,格式为IP:端口号')
args = parser.parse_args()
print('启动参数:')
print(f'Webdav服务器地址:{args.webdav_url}')
print(f'Webdav登入用户名:{args.username}')
print(f'Webdav登入密码:{args.password}')
print(f'文件输出路径:{args.output_path}')
print(f'是否下载字幕:{args.subtitle}')
print(f'是否下载电影信息:{args.nfo}')
print(f'是否下载图片:{args.img}')
print(f'遍历时是否显示文件夹路径:{args.show_path}')
proxies = None
if args.proxy:
proxies = {
'http': f'http://{args.proxy}',
'https': f'http://{args.proxy}'
}
directory, files, count = list_files(args.webdav_url, args.username, args.password, args.show_path, depth=None, path='', count=0, proxies=proxies)
urls = [args.webdav_url + item for item in directory + files]
download_count = 0
for url in urls:
if url[-1] == '/':
continue
filename = os.path.basename(url)
local_path = os.path.join(args.output_path, url.replace(args.webdav_url, '').lstrip('/'))
file_ext = filename[-3:].upper()
if file_ext in ['MP4', 'MKV', 'FLV', 'AVI', 'WMV']:
if not os.path.exists(os.path.join(args.output_path, filename[:-3] + 'strm')):
print('正在处理:' + filename)
try:
os.makedirs(os.path.dirname(local_path), exist_ok=True)
with open(os.path.join(local_path[:-3] + 'strm'), "w", encoding='utf-8') as f:
f.write(url.replace('/dav', '/d'))
except:
print(filename + '处理失败,文件名包含特殊符号,建议重命名!')
elif args.subtitle == 'true' and file_ext in ['ASS', 'SRT', 'SSA', 'SUB']:
if not os.path.exists(local_path):
download_file(url, local_path, filename, count)
download_count += 1
elif args.nfo == 'true' and file_ext == 'NFO':
if not os.path.exists(local_path):
download_file(url, local_path, filename, count)
download_count += 1
elif args.img == 'true' and file_ext in ['JPG', 'PNG']:
if not os.path.exists(local_path):
download_file(url, local_path, filename, count)
download_count += 1
progress = int((download_count / count) * 100)
print(f'已完成 {progress}%,共 {count} 个文件')
print('处理完毕!')
运行 strm 脚本#
-
启动一个 screen 会话(可选):
使用 screen 可以让你关闭正在运行脚本的终端窗口,使其在后台运行。
screen -S autofilm -
激活之前搭建好的虚拟环境
source /python_env/auto_film/bin/activate/python_env/auto_film/是你之前创建虚拟环境的路径。 -
运行脚本
请在运行脚本前确定媒体库里所有路径和文件名不包含
#《等特殊字符,否则会报网络错误。python3 autofilm.py --webdav_url https://alist.example.com/dav/your/media/ --username uname --password pword --output_path /your/strm/ --nfo true --img true- 把
https://alist.example.com/dav/替换为你的 alist 网址 - 把
your/media/替换为你媒体库在 alist 上的路径 - 把
uname和pword替换为你 alist 的用户名和密码 - 把
/your/strm/替换为你准备储存 strm 的位置
一些参数说明:
必要参数
- webdav_url:webdav 服务器地址
- username:webdav 账号
- password:webdav 密码
非必要参数
- output_path:输出文件目录,默认为当前文件夹的子目录 Media
- subtitle:是否下载字幕文件,默认 true
- nfo:是否下载 NFO 文件,默认 false
- img:是否下载 JPG 和 PNG 图片文件,默认 false
- 把
ok,请喝十杯茶🍵或看个电影🎞,脚本运行时间取决于你的媒体库大小和服务器配置,通常来说会🤏慢。
jellyfin 播放 strm 文件#
在 jellyfin 中添加媒体库,路径就选你储存 strm 文件的位置,jellyfin 会自动识别并刮削。
尝试播放,你会发现,根本不占用服务器带宽!🎉
后言#
这下可以不用担心服务器带宽,把 jellyfin 服务器公开出来了,等我再补补老番资源,咕~
参考